はじめに
配属された lab で、実際にデータを触って解析をし始めた。 今まではなんでも python でコードを書いて、可視化していたのだが、どうも毎回 python hogehoge.py と実行するのが面倒すぎる。 わざわざ python コードを書くのも嫌だし、ファイルが増えるのも嫌だと思うようになってしまった。
linux コマンドだけで片付くのであれば、それに越したことはない。 そんな中で出会ったのが datamash である。
本記事では datamash でできることとできないことを紹介し、できないことについてはその打開策を紹介する。
datamash について
公式サイトはこちら。
install 方法はシンプルなので、それぞれお願いします。 僕の場合はスパコンに元々入っていたので、この工程は飛ばします。
datamash でできること
できることを述べる
datamash 公式マニュアル
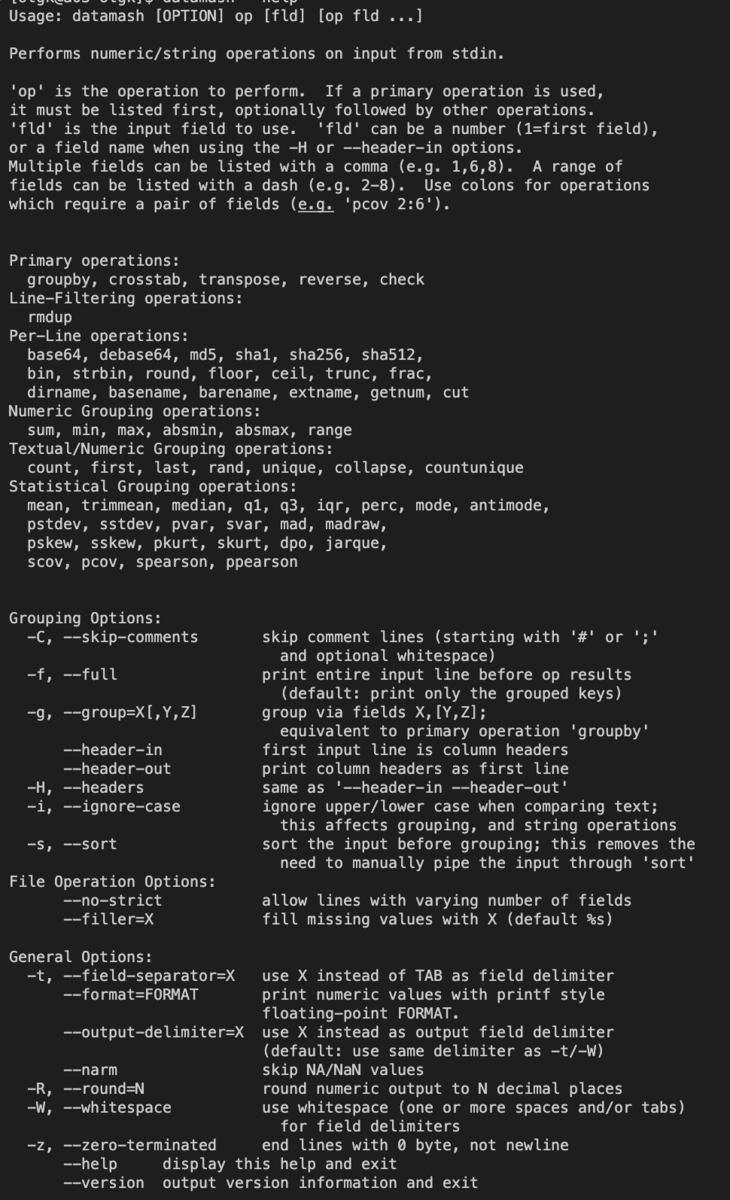
まとめると、
- 行・列の処理
- remove duplication (rmdup)
- groupby
- unique
- 統計値の計算
- sum
- mean
- mode
- count
が主だったものである。
datamash の利用
入力データの区切り文字はデフォルトでタブを受け付けている。 入力データの区切り文字を変えたければ、
datamash -t " "
とすれば、区切り文字を半角スペースにすることができる。
データセットの作成
echo -n > test_data.txt # initialization seq 21 | paste -d " " - - - >> test_data.txt seq 12 | paste -d " " - - - | awk '{print $1,$2+10,$3}' >> test_data.txt cat test_data.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 1 12 3 4 15 6 7 18 9 10 21 12
groupby
一列目について、groupby をする。そして、2列目のカウントを調べる。 cat test_data.txt | datamash -t " " -s -g 1 count 2
cat test_data.txt | datamash -t " " -s -g 1 count 2 1 2 10 2 13 1 16 1 19 1 4 2 7 2
これで OK. 1, 4, 7, 10 については二回登場しているので上手く grouping できている。
注意としては、
-g で grouping をする前に -s をつけて、sort 処理をしておくのが望ましい という点である。
-s をつけないと、
1 1 4 1 7 1 10 1 13 1 16 1 19 1 1 1 4 1 7 1 10 1
となってしまって、上手くいかない。これは盲点なので注意。
これは sum でもなんでも上手くいく。
cat test_data.txt | datamash -t " " -s -g 1 sum 2 1 4 10 22 13 14 16 17 19 20 4 10 7 16
また、unique というのもある。これは結構有能で、
cat test_data.txt | datamash -t " " -s -g 1 unique 2 1 12,2 10 11,21 13 14 16 17 19 20 4 15,5 7 18,8
という感じ。unique をカンマ区切りで出してくれる。要は、groupby の get_member() 的なことができる。
groupby では、first や countunique のような機能もある。 groupby 演算ではやりたいことはほとんどできるはず。
正直私は、
- groupby で grouping してカウントや sum を計算する
といった使用方法が主である。
datamash でできないこととその代替案
SQL でいうところの、where 構文など、datamash ではできないことも存在している。
SQL の where 構文
select * where Col1 > 10 のようなことをしたいとする。 datamash ではそれはできないので、以下のように awk を使うのが良い。
cat test_data.txt | awk '$1>10 {print $0}' 13 14 15 16 17 18 19 20 21
awk の出力をさらに受け取って、datamash で処理することもできる。
Col1 と Col2 の和が 15 以上のものについて、groupby Col1 count 2 Col2 をやりたいのなら、
cat test_data.txt | awk '$1+$2>=15 {print $0}' | datamash -t " " -s -g 1 count 2 10 2 13 1 16 1 19 1 4 1 7 2
SQL の select 文
表形式のデータから、特定の列だけを取り出したいとき、
- 演算を伴う時
- 演算を伴わない時
の二つのケースがある。
演算を伴う時
awk で書けば OK. test_data.txt の1列目と2列目の和と積を計算し、2列に表示するとする。 すると、
cat test_data.txt | awk '{print $1+$2, $1*$2}' 3 2 9 20 15 56 21 110 27 182 33 272 39 380 13 12 19 60 25 126 31 210
演算を伴わない場合
awk で簡単に書くことはできるのだが、'{print}' を書くのが面倒な時があるので、そういったときは、cut を使うと、閣僚がほんの少し減る気がするし、 cut コマンドはそんなに複雑なことができないので、後でスクリプトを追うときに、やっていることが分かりやすいというメリットがあると思っている。 なので、cut で済む操作は awk ではなく cut を使うようにしている。
以下のコードで、test_data.txt を " " 区切りで読んだ時の 1, 2 列目を取り出している。
cat test_data.txt | cut -d " " -f 1,2 1 2 4 5 7 8 10 11 13 14 16 17 19 20 1 12 4 15 7 18 10 21
ヒストグラムによる可視化も linux で。
結局ここまでの datamash を用いたデータ集計を行なっても、可視化のフェーズでpython に頼るのが悔しい。 ということで、ツールを探したところ、少し良さそうのものがあったので、紹介する。
標準入力からヒストグラムを描画するCLIツールを作った - さんちゃのblog
このツールを導入すれば、
cat alignmentscore_dist.txt | hist 569|******************************************************************************** 1451|********************************************* 2333|************************************** 3215|********************************** 4098|********************************************** 4980|****************************** 5862|*********************** 6744|************************** 7626|******************************** 8508|***************************** 9390|**************************** 10273|******************************** 11155|************************ 12037|**************************** 12919|****************************** 13801|*********************** 14683|********************* 15565|**************************** 16447|**************************** 17330|************************* 18212|************************** 19094|**************************** 19976|*********************** 20858|************************* 21740|********************** 22622|************************ 23505|********************** 24387|******************** 25269|*********************** 26151|****************************************** +--------------------------------------------------------------------------------+ 65368 times +----------------------------------------+ 32684 times
のように、気持ちのよい histgram を作成してくれる。
注意として、hist は、サンパルサイズが小さいとバグ的な挙動をする。
最後に
histgram を作成し、最低限の可視化を行うところまで、python に頼らないでできることになった。 これは結構でかい。
読者の皆様も、おすすめのツールがあればコメントで教えてください!